We’re sorry to inform you that we have shut down.
Postponavirus Prototype: Using Machine Learning to discourage disease transmission via face-touching
I'm building a little project to try to improve public health and the spread of pandemic diseases through the use of machine learning and behavior modification with operant conditioning. It identifies gestures and plays a sound when it detects certain unwanted behavior.
https://youtu.be/5JHZU2kdaqw
This project seeks to help users practice behaviors that limit the transmission of pathogens that occur via hand-to-face contact. Face touching (particularly of the mouth, nose, and eyes) can lead to an increased probability of infection from various microorganisms. By using trained pose-detection models that detect these behaviors, we can notify the user of unwanted actions, allowing them to improve their behavior patterns. The process of Operant Conditioning can slowly change behaviors over time and lead to better health outcomes.
How could I improve this for others to use?
Designing for the New A(I)udience
How will design trends evolve to address the emergence of a new audience of Machine Vision and its integration with human perception?
Background
Trends in design have varied dramatically over the years to adapt to the ever-changing expectations of audiences. As technology advances and integrates with humans, our very perception of the world is enhanced. Computer Vision operates using distinctly different techniques than human vision. By examining differences in these complementary modalities, we can adapt new design patterns better suited for communication to both audiences.
Over the last couple of years I've become really excited with the Machine Learning tools that have become available(Turicreate, CoreML, tensorflow etc). After testing different workflows of various Object Detection and Image Annotation technologies I began to notice a pattern in detection performance that seems to be present across each of them.
Simply Shaped Flat logos are hard to detect with Computer Vision.
The current trends of Material or Flat Design create some very elegant and intuitive products that are pleasing to the human eye. Unfortunately, this is not the case for our AI friends, which rely upon shape and pattern complexity for object detection. The fewer visible significant features of an object, makes the job of recognition more ambiguous, leading to mis-categorization and false positives.
By understanding this aspect of computer vision, you can choose to emphasize or de-emphasize objects in Computer Vision by adjusting certain design parameters. These principles are consistent across 2D/3D/XR context. The most obvious design features that influence recognition are texture and shape.

Testing
Take, for example, how the Budweiser logo has changed over time and compare the performance of a naively trained image recognition model across these different logos. What immediately becomes apparent is that the newest, and according to my design sense, the 'best looking' logos are less likely to be detected by the tool. Take a look at the shape complexity of the logos. Notice how the flat icons are often omitted, while those with more complex shading and texture are more accurately recognized. What other features stand out to you?
A 2 Audience Approach
By understanding these differing perspectives, we can develop a new system of visual communication that speaks to both of these audiences. There may be times where creating a unified design theme is perceived equally well with both human and machine, but I think there is an opportunity to utilize their differences to our advantage. Let’s examine the possibilities of visual communication outside the bounds of human perception.
Imagine a scenario where a sign contains 1 image that can be viewed by humans, and another invisible image, superimposed upon the first with information printed in the Infra-Red or Ultraviolet spectrum to communicate with through computer vision without the need to modify or compromise the design of either. Much of the existing imaging technologies we carry with us are optimized for the wavelengths between 400 to 700 nm, so alternative imaging solution would need to be implemented. There are some off the shelf approaches that could be used to encode information in a resilient and robust way.
Infrared or Ultraviolet Printing of embedded data in QR codes offers improved object salience without impacting other human design requirements. We can modify existing signage with UV stenciling or design new more robust systems that integrate dual This design pattern has implications for roadsigns, disability tools, fonts, camouflage, marketing or any XR application.
Self-Driving Cars and Roadsign design - How should road marking and signs be improved for easier detection by computer vision? What other information could be embedded in static or dynamic signage? Imagine lane separators that indicate upcoming interchange information, Offramp Distance with Curve information. Toll lanes, interchange information, turn vector information, environmental warnings, speed limits, and parking zone information.We can imagine a Global initiative to improve signage used for navigation. This could drastically improve the time to market for self-driving cars and other automation processes. There could be digital signage, with human readable information as well as real-time encoded data such as current traffic, emergency services and weather conditions in the non-visible spectrum.
How can we improve disability tools? Aided by computer vision such as text to speech enhanced with embedded information, we could augment a users awareness of their surroundings. Maybe UV/IR Machine Vision enhancements to braille?
How can companies improve their salience in a computer vision context?
Post your ideas in the comments below.
Videos Generated from Still Images using SinGAN
We discovered a new technique for generating video from still images using machine learning(SinGAN). This project lead to some really interesting results! (Technical Details below). Post an image link in the comments and we’ll see what arises!










SinGAN: Learning a Generative Model from a Single Natural Image
Tamar Rott Shaham, Tali Dekel, Tomer Michaeli
(Submitted on 2 May 2019 (v1), last revised 4 Sep 2019 (this version, v2))
We introduce SinGAN, an unconditional generative model that can be learned from a single natural image. Our model is trained to capture the internal distribution of patches within the image, and is then able to generate high quality, diverse samples that carry the same visual content as the image. SinGAN contains a pyramid of fully convolutional GANs, each responsible for learning the patch distribution at a different scale of the image. This allows generating new samples of arbitrary size and aspect ratio, that have significant variability, yet maintain both the global structure and the fine textures of the training image. In contrast to previous single image GAN schemes, our approach is not limited to texture images, and is not conditional (i.e. it generates samples from noise). User studies confirm that the generated samples are commonly confused to be real images. We illustrate the utility of SinGAN in a wide range of image manipulation tasks.
SinGAN, an unconditional generative model that can be learned from a single natural image. Our model is trained to capture the internal distribution of patches within the image, and is then able to generate high quality, diverse samples that carry the same visual content as the image https://arxiv.org/abs/1905.01164
Automated Colorization of Black and White Images
Market St in San Francisco in 1906(before the fire)








.Automated Colorization has come a long way. Using some off the shelf tools like FastAI and DeOldify, you can get some pretty fantastic results. If you have any B&W photos you’d like me to test, please post them in the comments, and I’ll process the image.
These home movies of Frida Kahlo turned out pretty great imo.
If you want to collaborate:
https://colab.research.google.com/drive/1ZvErWgAXvAvtPmwKeCPCaVIE2pstF3gp
UI Updates for ColdSpotting!
ColdSpotting just release a brand new version! New live charting of pings help you isolate recent network conditions. We added a requested feature to allow users to set a custom Destination IP so that users can test specific network endpoints!
See No Evil
Here is our first test of a Realtime Logo Detection and Obfuscation in Augmented Reality. Doing some research on iOS for a way to remove advertisements from an AR context. I'm not sure how well this will scale, or how much training i'll need to improve it, but its fun to play with right now. What should I try? I could try some brand replacement. Maybe try some GLSL shaders instead of the current 2D plane.
Utilizing Viral Youtube Challenges as Curated Data Sets for Deep Learning
Google just published a really interesting article about how they developed their depth estimation algorithm using data from a popular viral "Mannequin challenge". This popular YouTube challenge had people in a variety of scenarios holding rigid poses while a handheld camera moves through the scene. This provides a fantastic data set as humans are usually the salient target of a camera and the complexity of kinetic human movement creates additional computational complexity that isn’t present in this data. This challenge had diverse participation from all over the world and in vastly differing settings providing a particularly useful data set.

The results are incredible
Using over 2000 videos they were able to achieve fantastic results when compared with other state-of-the-art depth estimation approaches.

After looking at the successful utilization of these crowd-sourced data sets, what other utility can be drawn from other available viral video data sets?
The ALS Ice Bucket Challenge and the Onset of Hypothermia
The first thing that came to my mind was the ALS Ice Bucket Challenge, in which participants are doused with ice water while there reactions are filmed. This curated data set shares some of the valuable features of the Mannequin challenge, but instead offers us a different avenue of investigation. Can we use data from these videos to detect the symptoms of hypothermia or other temperature induced maladies? There are almost 2 million results when searching for the "Ice Bucket Challenge". We have a remarkable opportunity to use these memes to generate valuable insights into human reactions to stimuli.
Cinnamon Challenge and Respiratory inflammation
I don't advocate anyone give this one a try, but the Cinnamon Challenge had participants attempt to swallow a spoonful of cinnamon which would cause most individuals to violently cough and inevitably inhale fine particles of cinnamon. The individuals experience a high degree of respiratory distress, and once again are captured on camera for us to analyze.
Just looking through the list of viral challenges, a few look like they could provide valuable medical insights and may be worth investigating.
Ghost Pepper Challenge - Irritation/Nausea/Vomiting/Analgesic Reactions
Rotating Corn Challenge - Loose Teeth/Tooth Decay/Gum Disease
Tide Pod Challenge - Poisoning
Kylie Jenner Lip Challenge - Inflammation/Allergic reactions
Car Surfing Challenge - Scrapes/Lacerations/Bruising/Broken Bones/Overall Life Expectancy
What other Challenges can provide insight for us?
References:
Learning Depths of Moving People by Watching Frozen People
https://www.youtube.com/watch?v=fj_fK74y5_0
Moving Camera, Moving People: A Deep Learning Approach to Depth Prediction
https://ai.googleblog.com/2019/05/moving-camera-moving-people-deep.html
You can read "Learning the Depths of Moving People by Watching Frozen People" here:
https://arxiv.org/pdf/1904.11111.pdf
Acknowledgements
The research described in this post was done by Zhengqi Li, Tali Dekel, Forrester Cole, Richard Tucker, Noah Snavely, Ce Liu and Bill Freeman. We would like to thank Miki Rubinstein for his valuable feedback.
e2 Tally System using Octopus and Swift
There is no perfect, off-the-shelf solution for Tally with e2, so we built our own using Octopus OSC and Swift.
ColdSpotting - Wifi Network Diagnostics in Augmented Reality
Visualize and Diagnose Wifi Network Signal Strength with ColdSpotting.






Visualize the strength of your WIFI network in real-time and in Augmented Reality.
Find deadspots where your reception isn't well covered.
Diagnose poor network performance.
Perform site surveys to ensure high-reliability for mission critical events.
Test using real-world devices.
Compare coverage across manufactures and product lines.
Perfect for:
- IT Installers
- AV Systems Engineers
- Home Entertainment Enthusiasts
- Video Gamers
- Network Administrators
- Educational Institutions
Requires iOS 11.2 and and iPhone 7 and above.
You can sign up for our mailing list and a TestFlight invite here:
http://www.showblender.com/coldspottingmailinglist
More information will be added at
http://www.showblender.com/coldspotting
First Tests of Realtime iOS Augmented Reality
First tests of a Realtime iOS Augmented reality prototype using ARToolkit. Really great framework. It amazes me how fast technology advances.
aiBias - Image Detection Celebrity Roundup

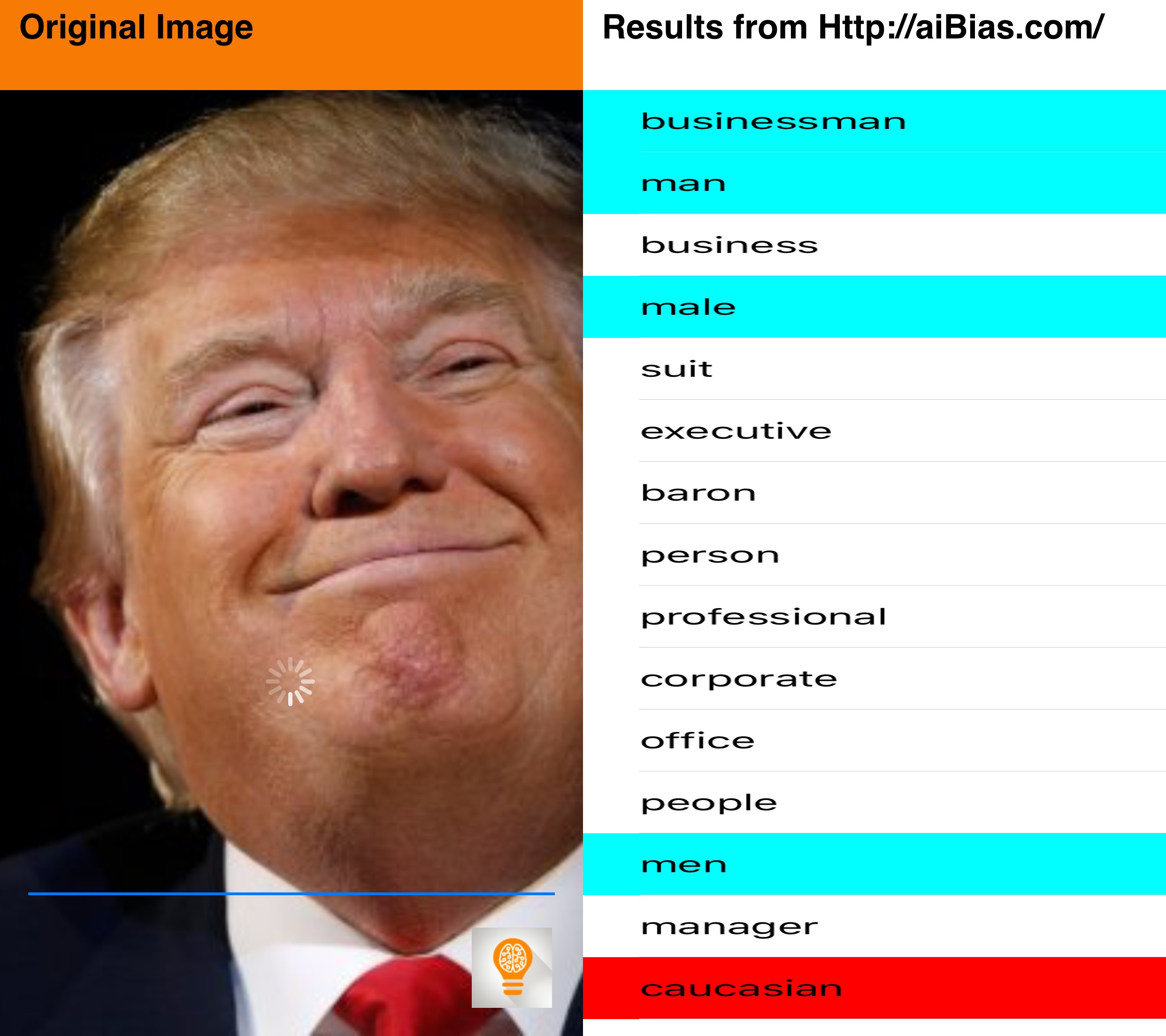


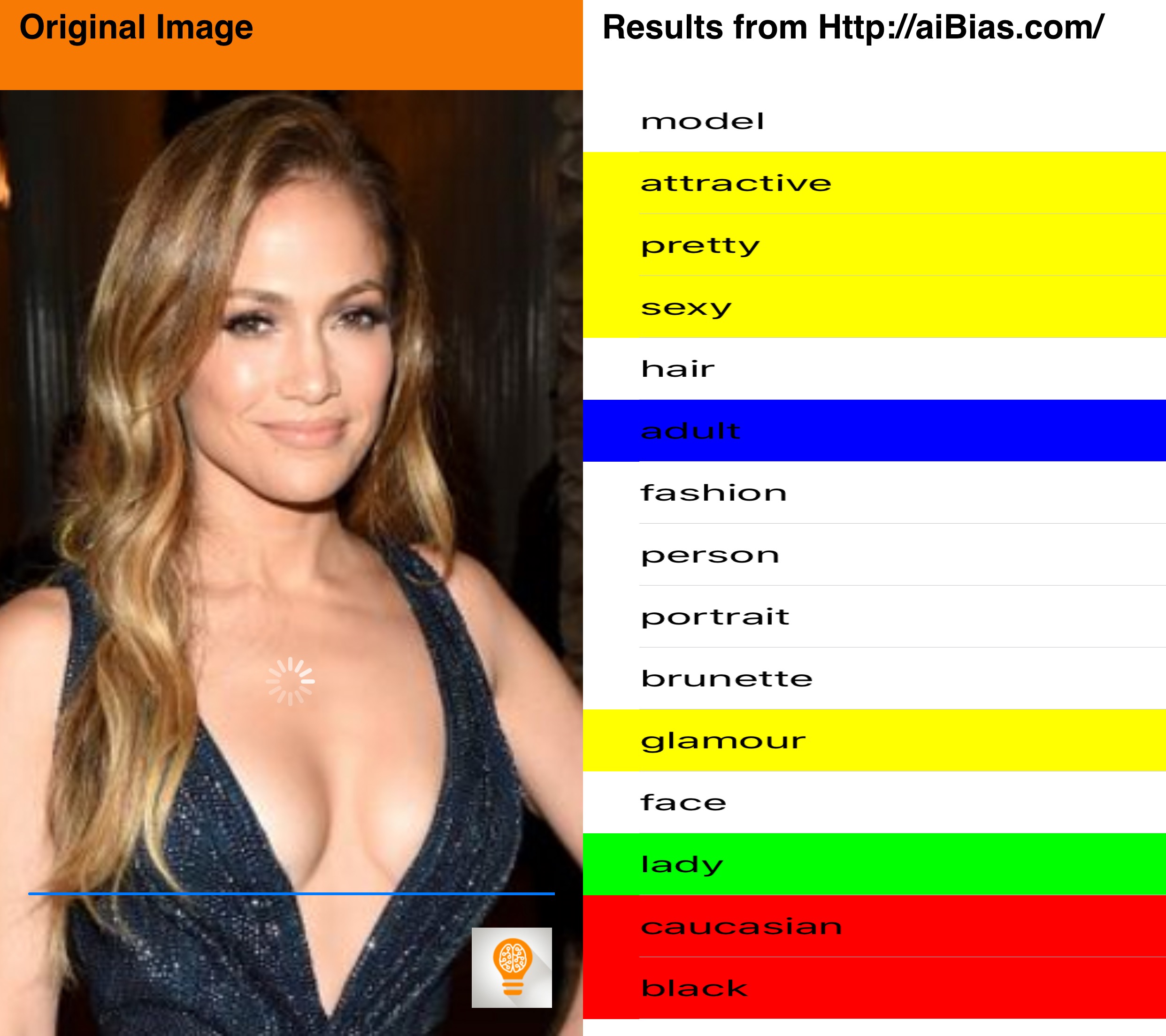
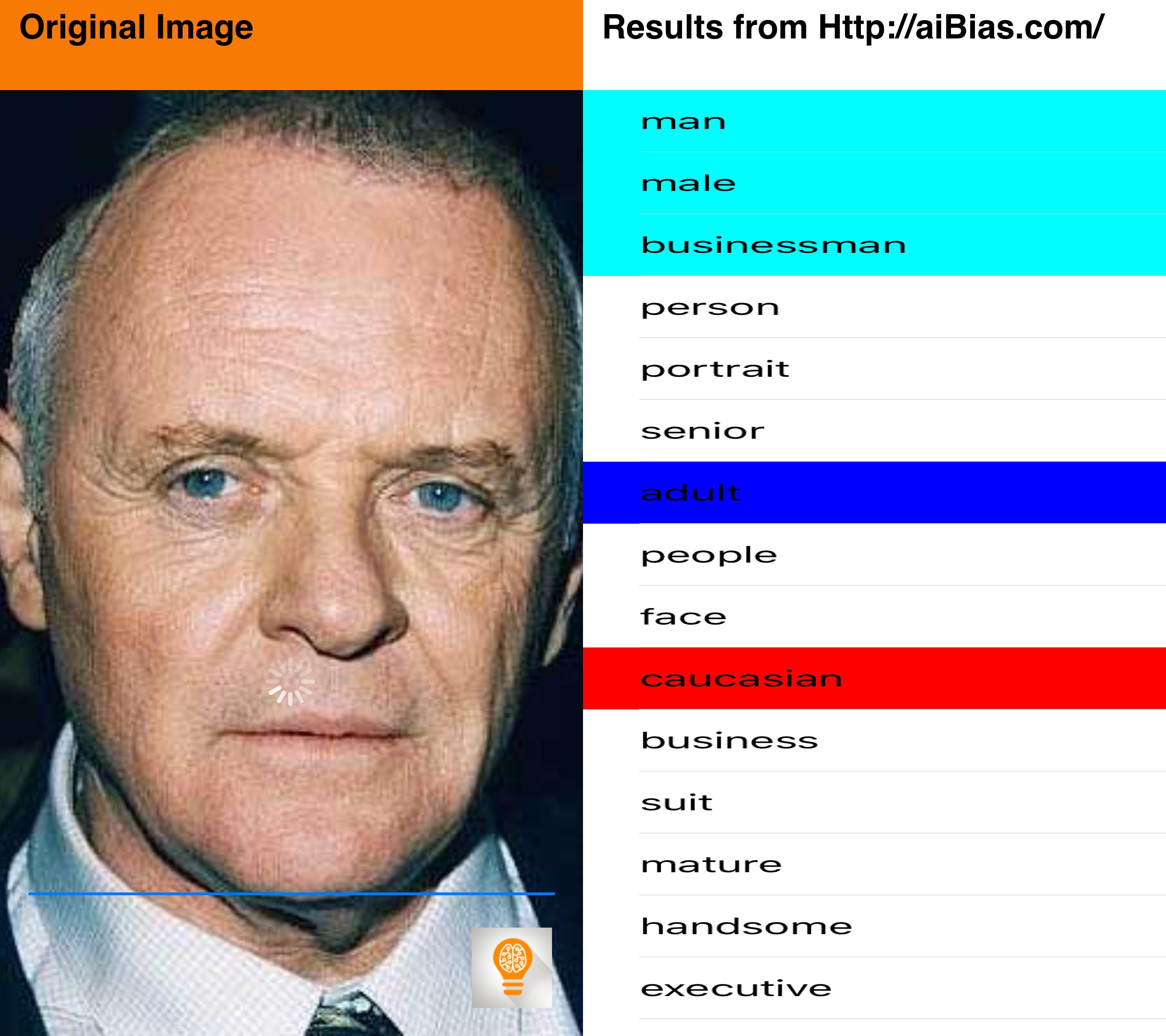
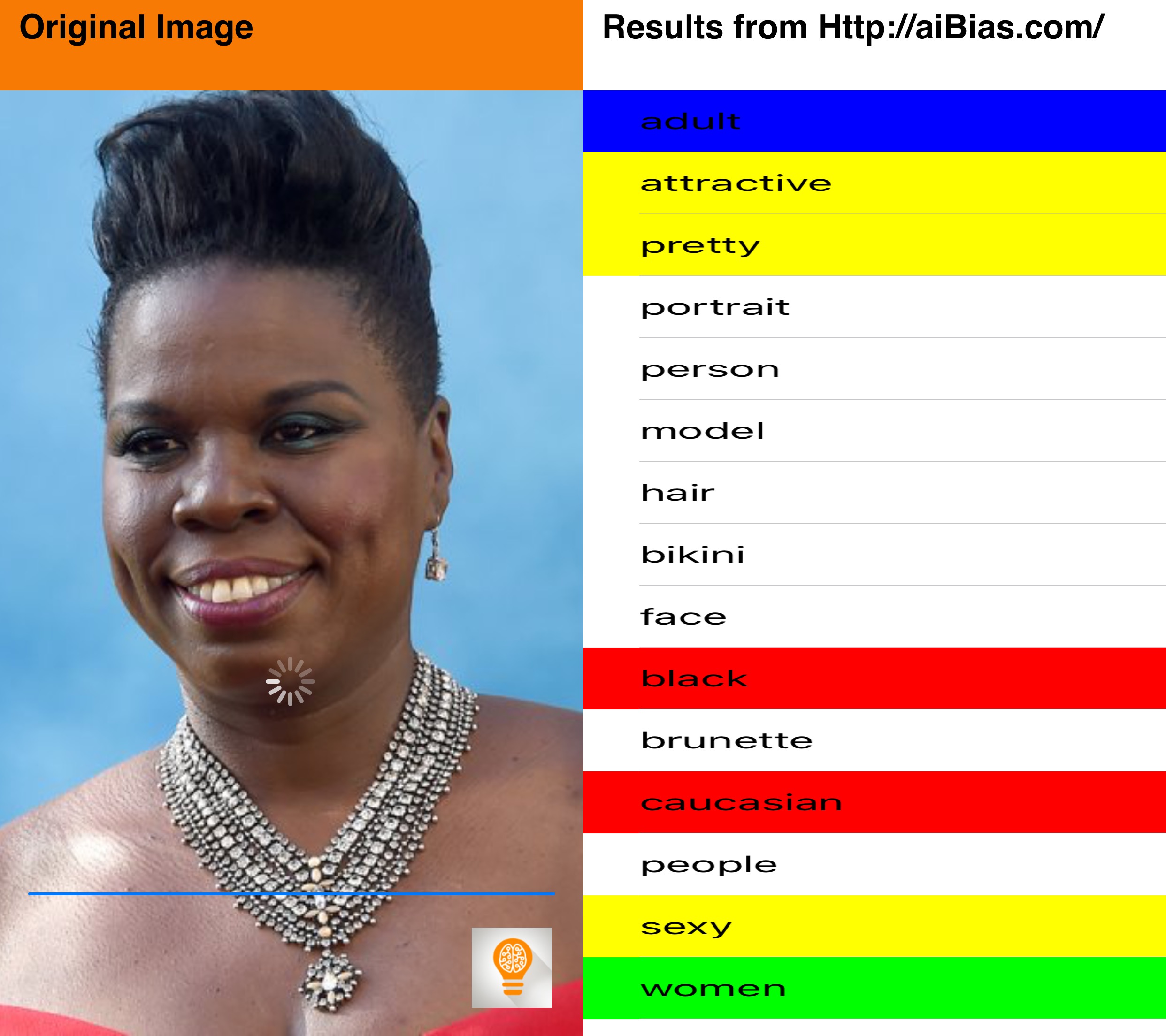




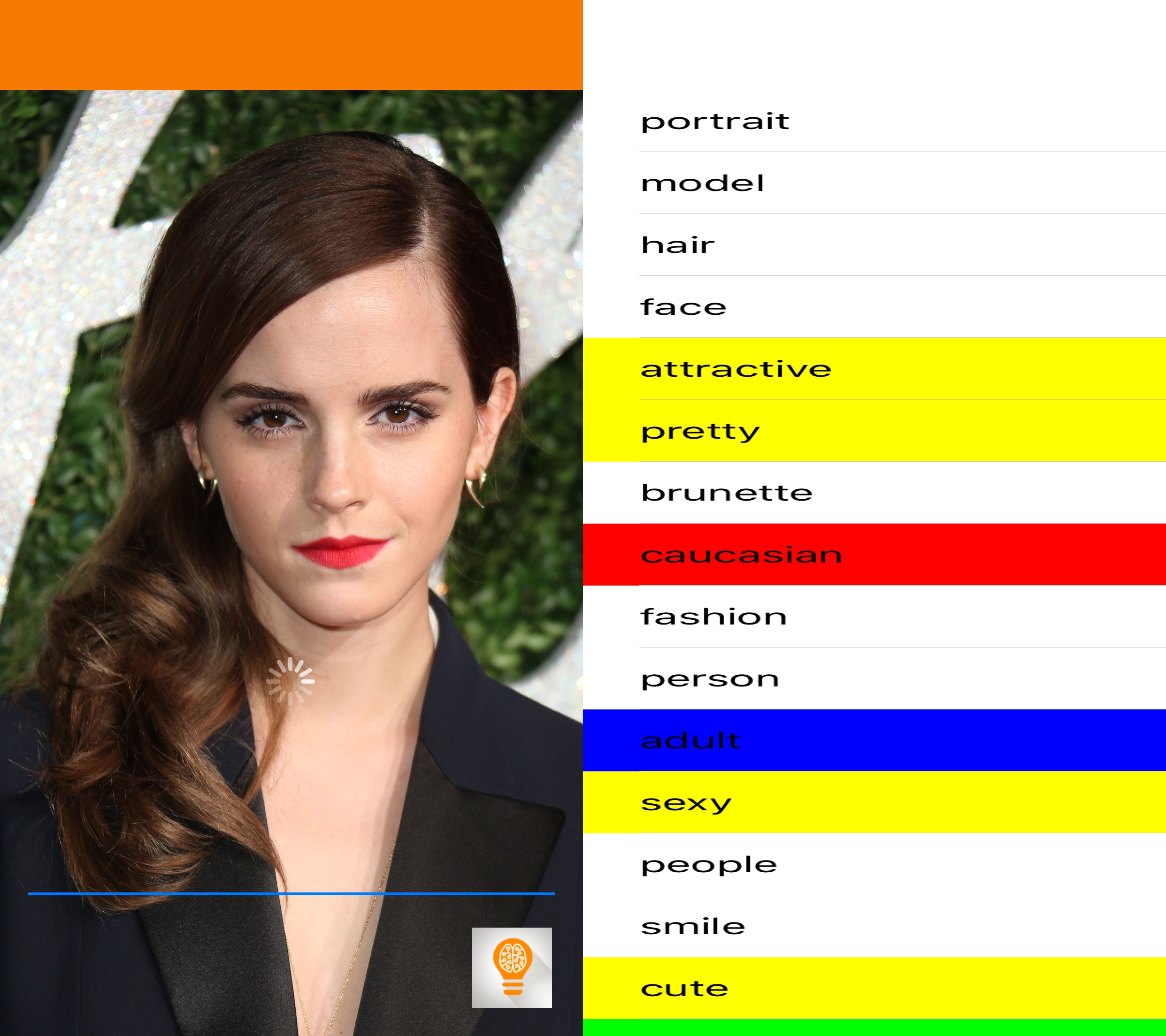



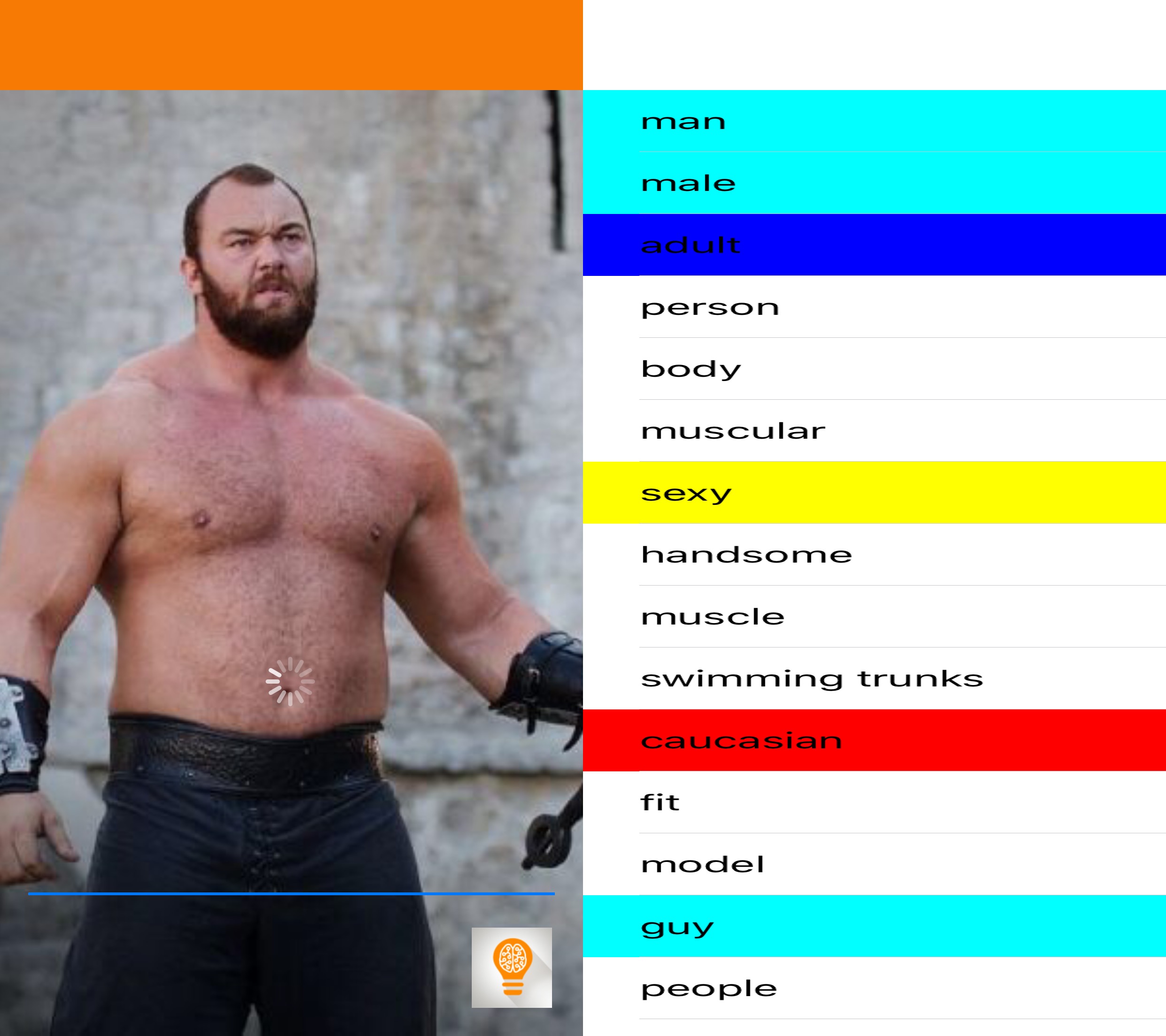



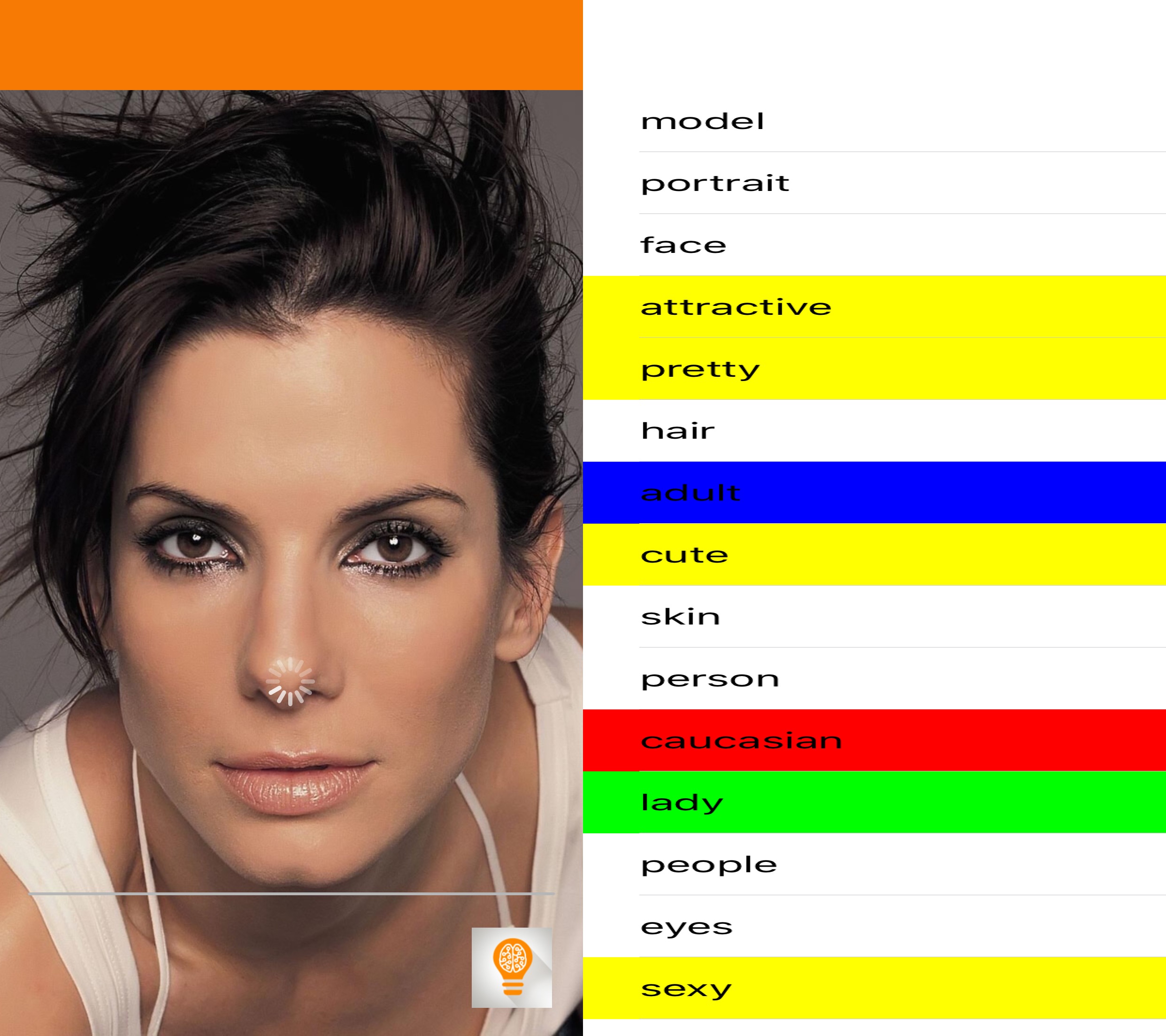









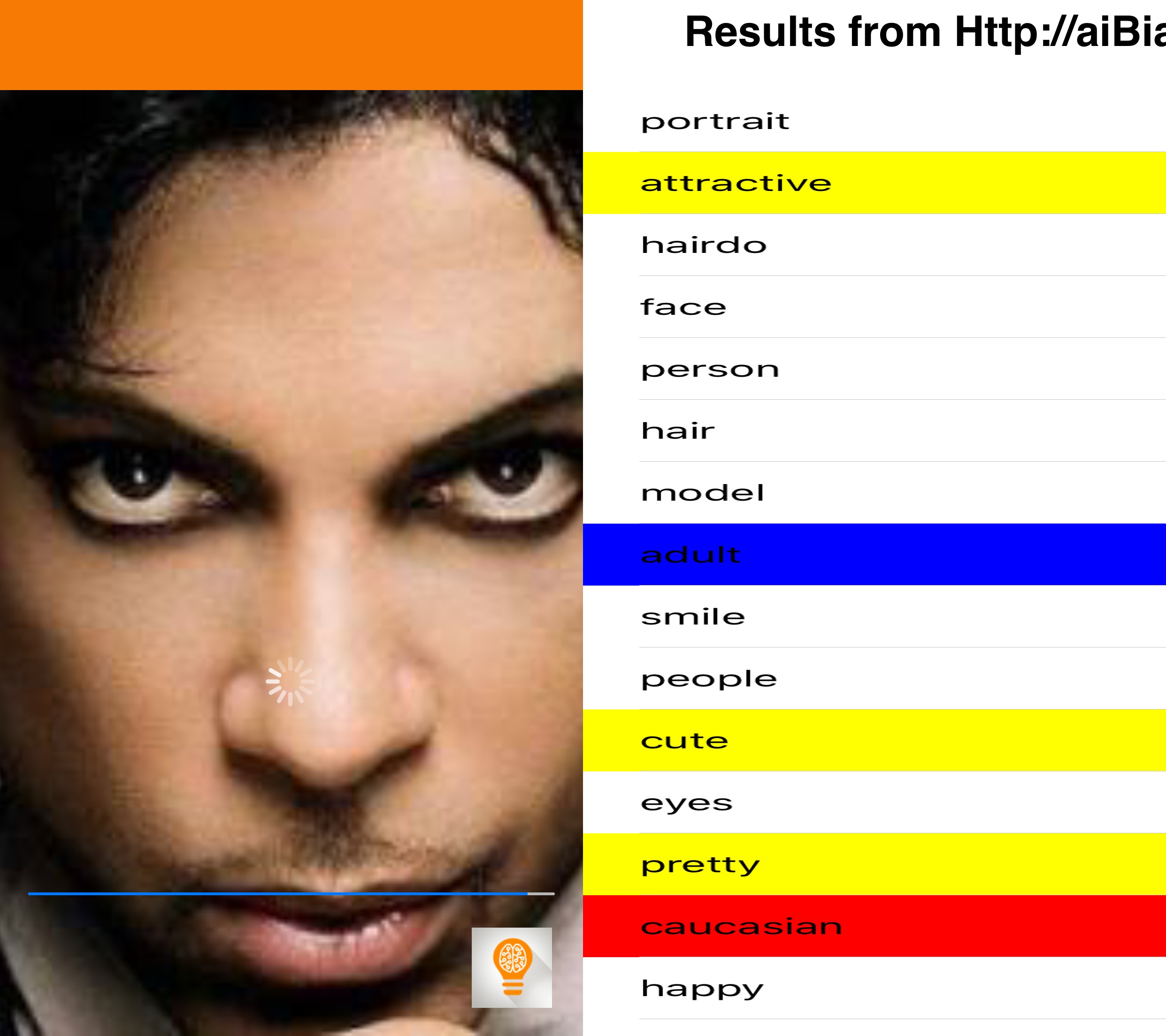
I did a little testing of aiBias with some celebrity photos I found online. Let me know what you think in the comments.
Have you ever wondered how machines see you?
Have you ever wanted a glimpse into what a computer sees?
Now you can, with aiBias you are able to take a photo(or use existing photographs from your Photo Library) and upload it to the cloud for processing. After detecting objects in the photo, the resulting tags will be displayed. Beginning with the highest confidence results take a look at the results and see what kind of terms are being used. We’ve included syntax highlighting for some particularly interesting categories(including race, gender, age, profession).
What does AI think about gender and race?
How is the data seen as significant, and under what circumstances should it be used?
Should AI be designed such that it is "color blind"?
See trends and changes in results over time?
Will AI learn to conform to our cultural norms or shape them?
aiBias.com
For more information:
http://www.showblender.com/blog-1/2016/7/7/ai-continued-studies-with-image-recognition
http://www.showblender.com/blog-1/2016/6/27/ai-bias-questions-on-the-future-of-image-recognition
e-mail me your e-mail address for a free Beta invite to the iOS app.
joe@showblender.com
AI Bias - Requests for iOS Beta Testers!

If you are interested in joining the free iOS beta program for aiBias please send an e-mail to joe@showblender.com and I will send you a link to try it out. It's more fun than you think!

AI Bias - Continued studies with Image Recognition
This 4th of July weekend I had a chance to experiment with the Image Recognition Platform mentioned last week and on the blog. Using a popular off the shelf(PaaS) image recognition service, I've begun submitting photos and capturing their provocative results. The process brings up a lot of questions on the future of machine learning, with a focus on possible biases that may be introduced into such systems.
Showcase: Submission Photos with the Resulting Tags Sorted by Highest Confidence:
Example #1

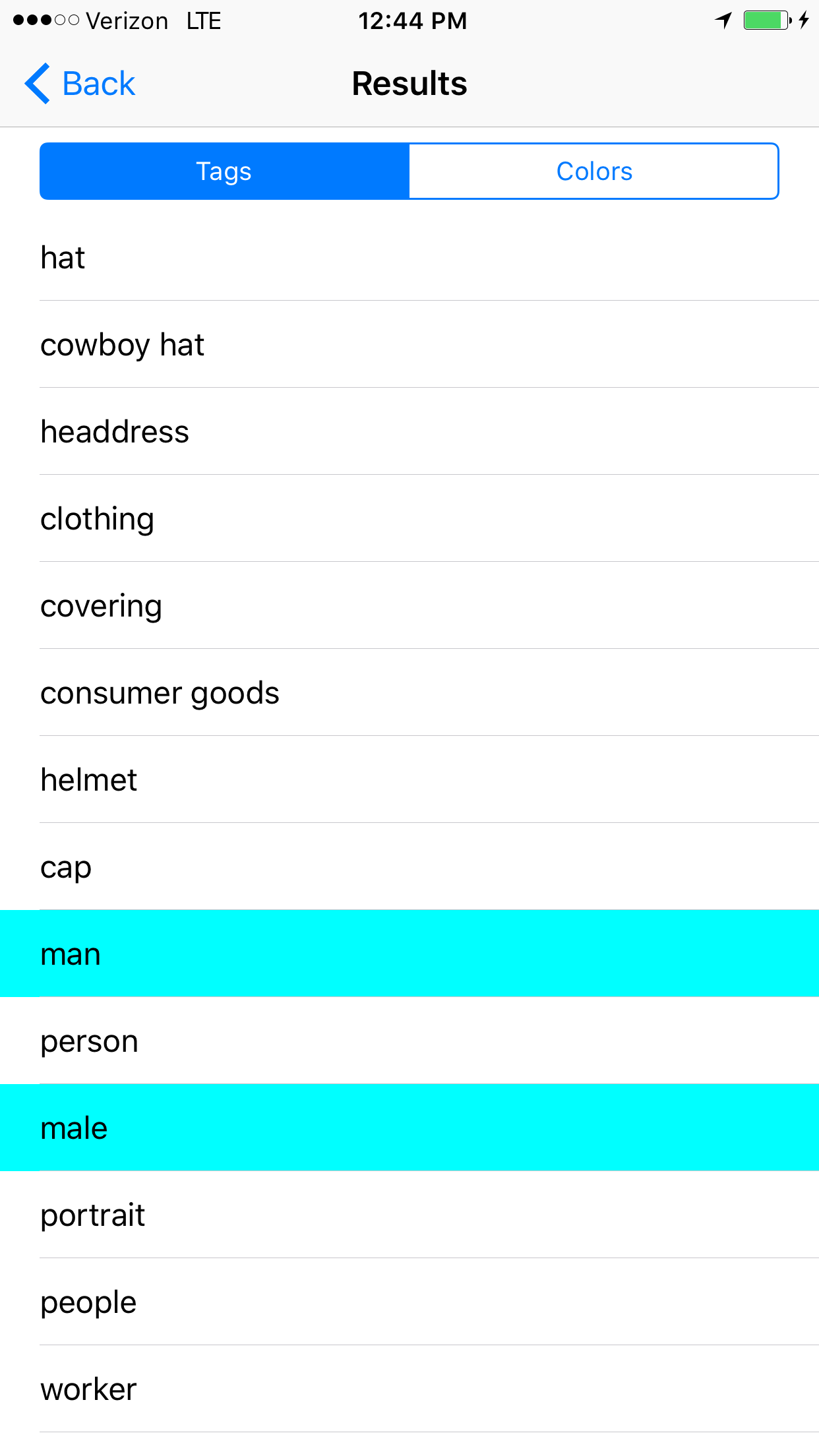

Notable Results: Detected the hat pretty well, gender, used the term 'worker', detected caucasian, adult.
Does the algorithm have any correlations between the term 'worker' and gender or race?
Example# 2


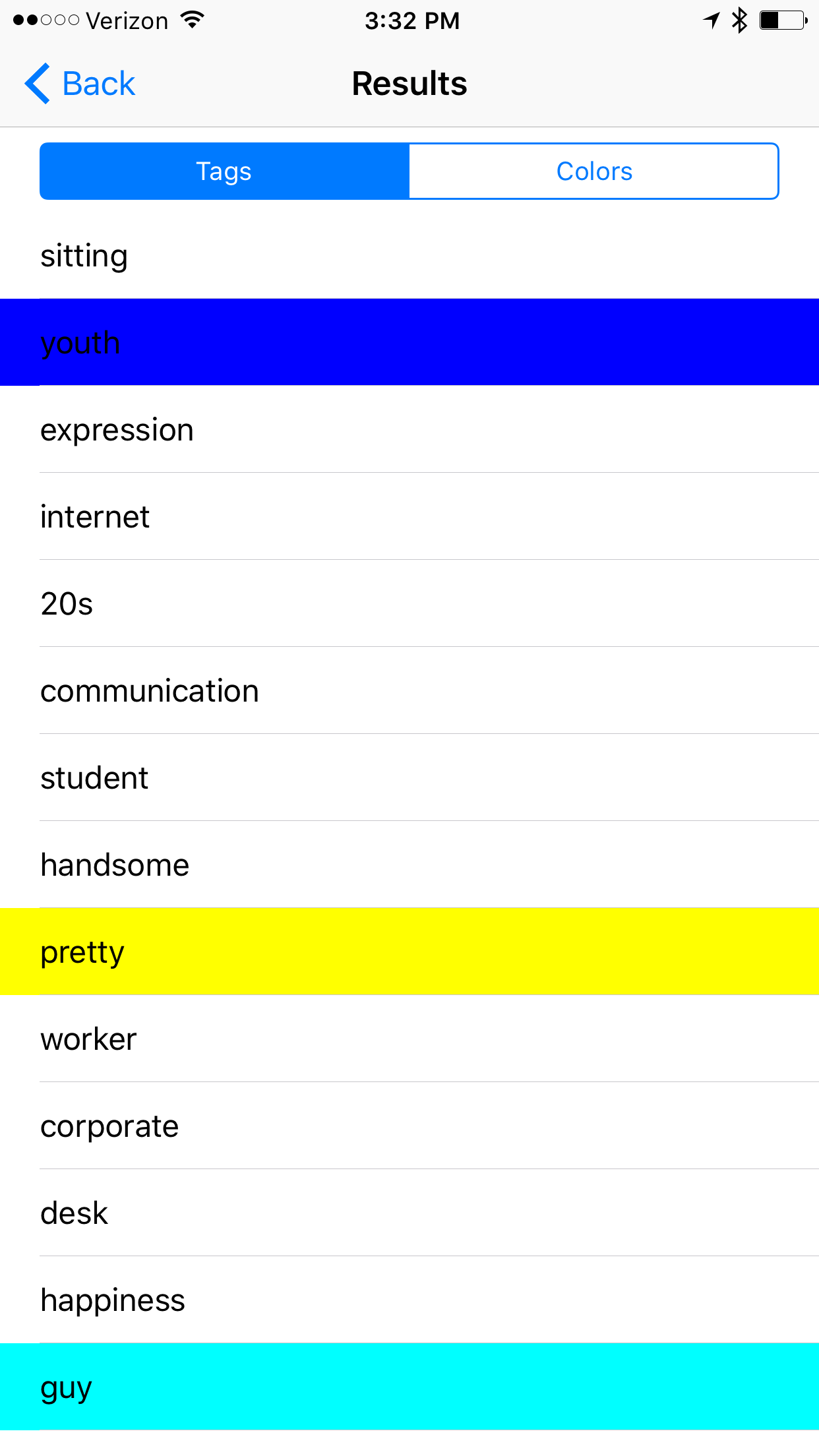
Notable Results: High confidence adult, male, caucasian, business, work, computer, internet, 20s, corporate, worker,
There is no computer or internet in the photo yet there are many career related results. I'm not sure why this image evokes such responses (Are Ray-Bans highly correlated with the tech sector?).
Example #3

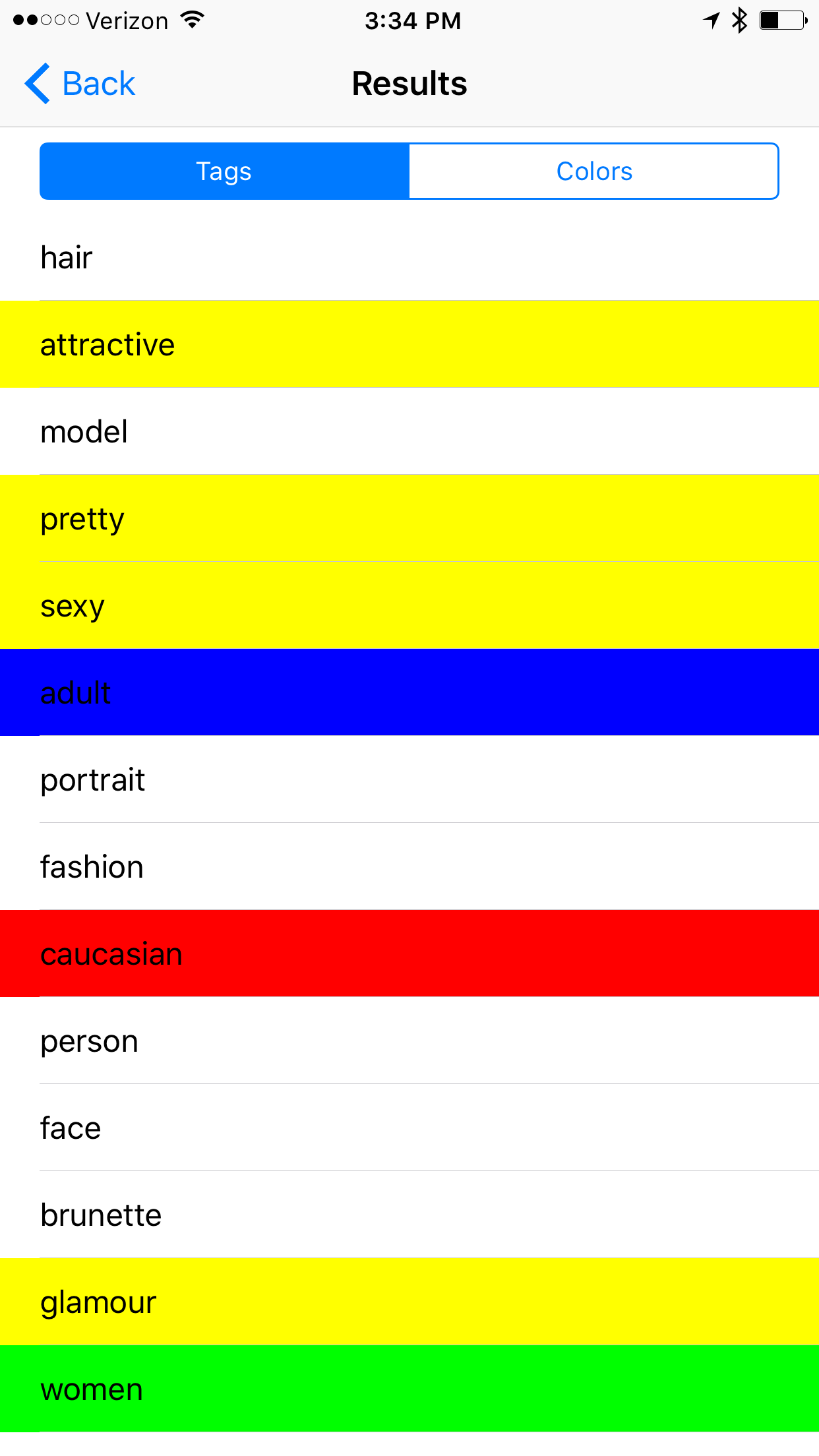

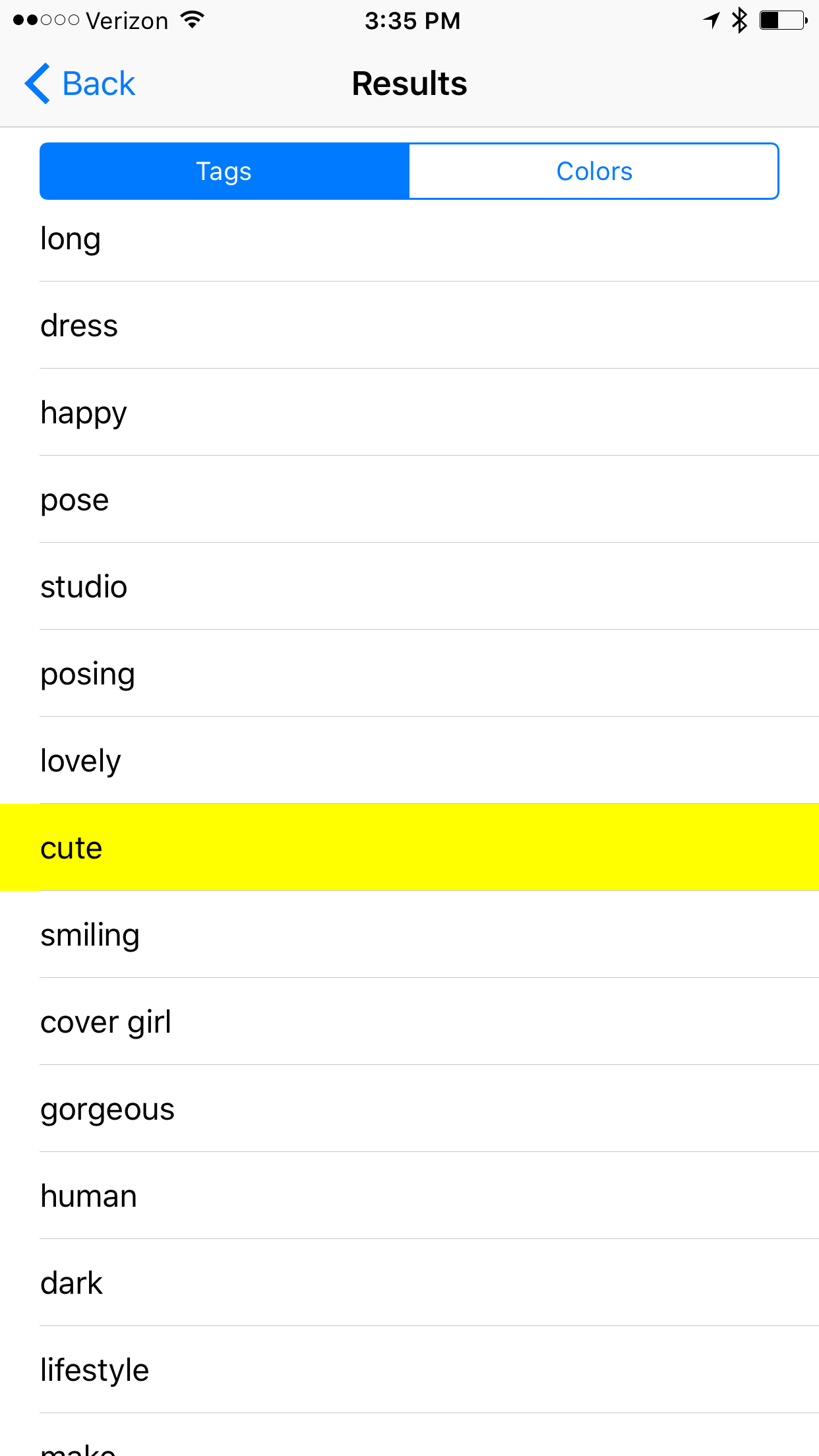

Notable Results: attractive, pretty, glamour, sexy, age and race are present, sensuality, cute, gorgeous,
It seems like the tags returned from images of women have very differing focus. While male images return terms that reflect upon interests or jobs, images of women results often using qualitative descriptors of their physical bodies. Model was listed, but not the tag worker, which we see more generally applied to male images.
Example #4

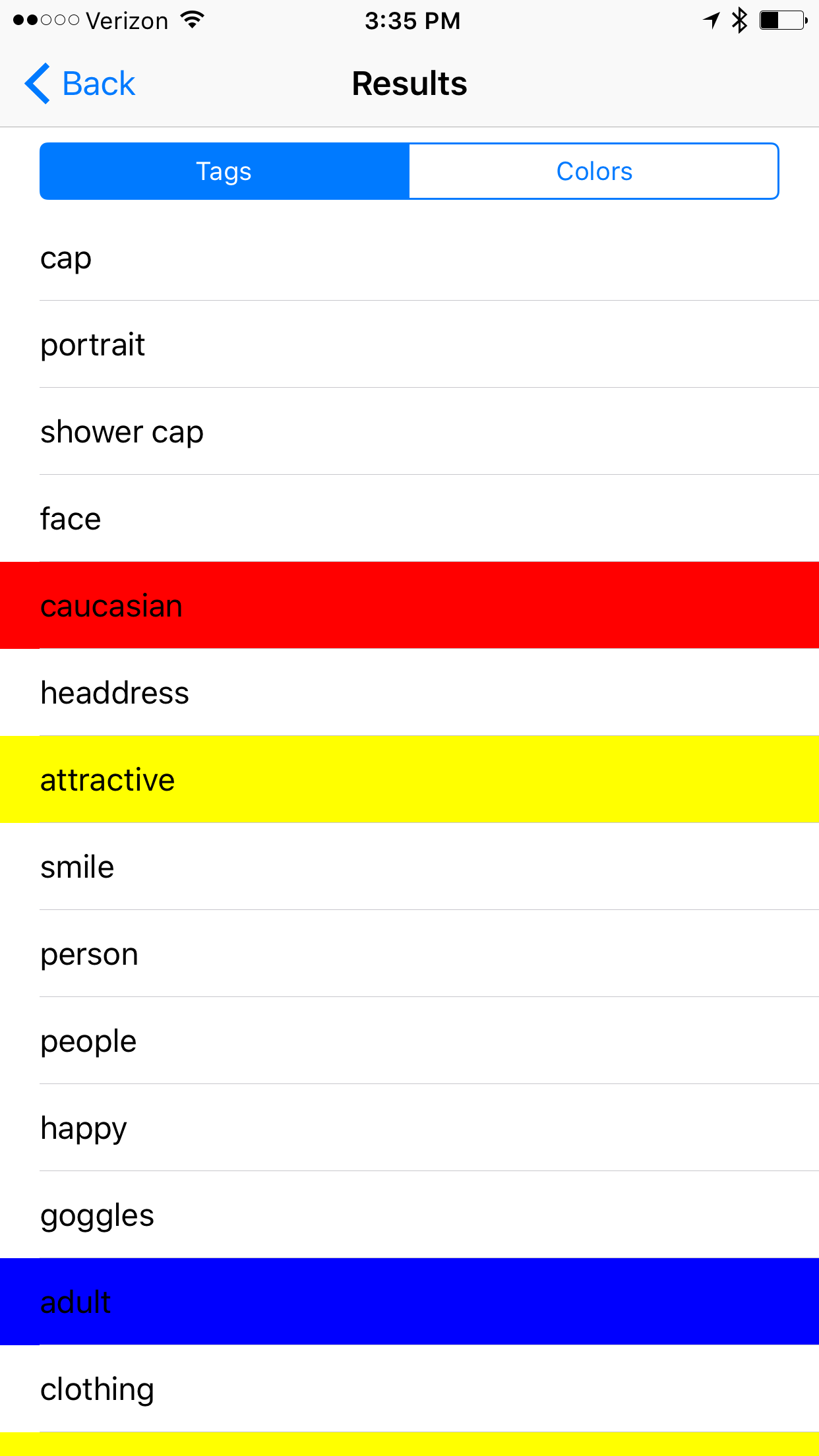
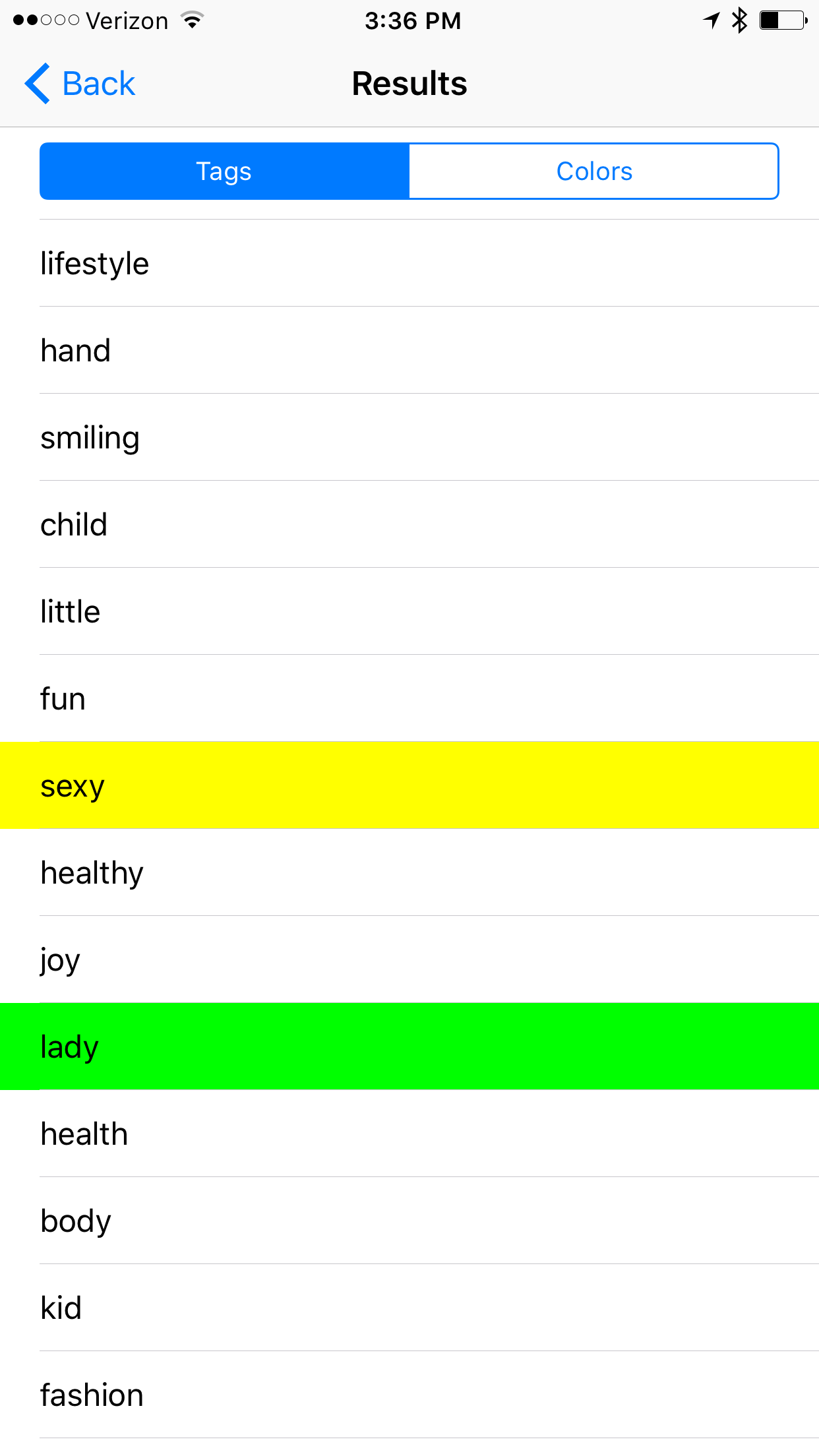
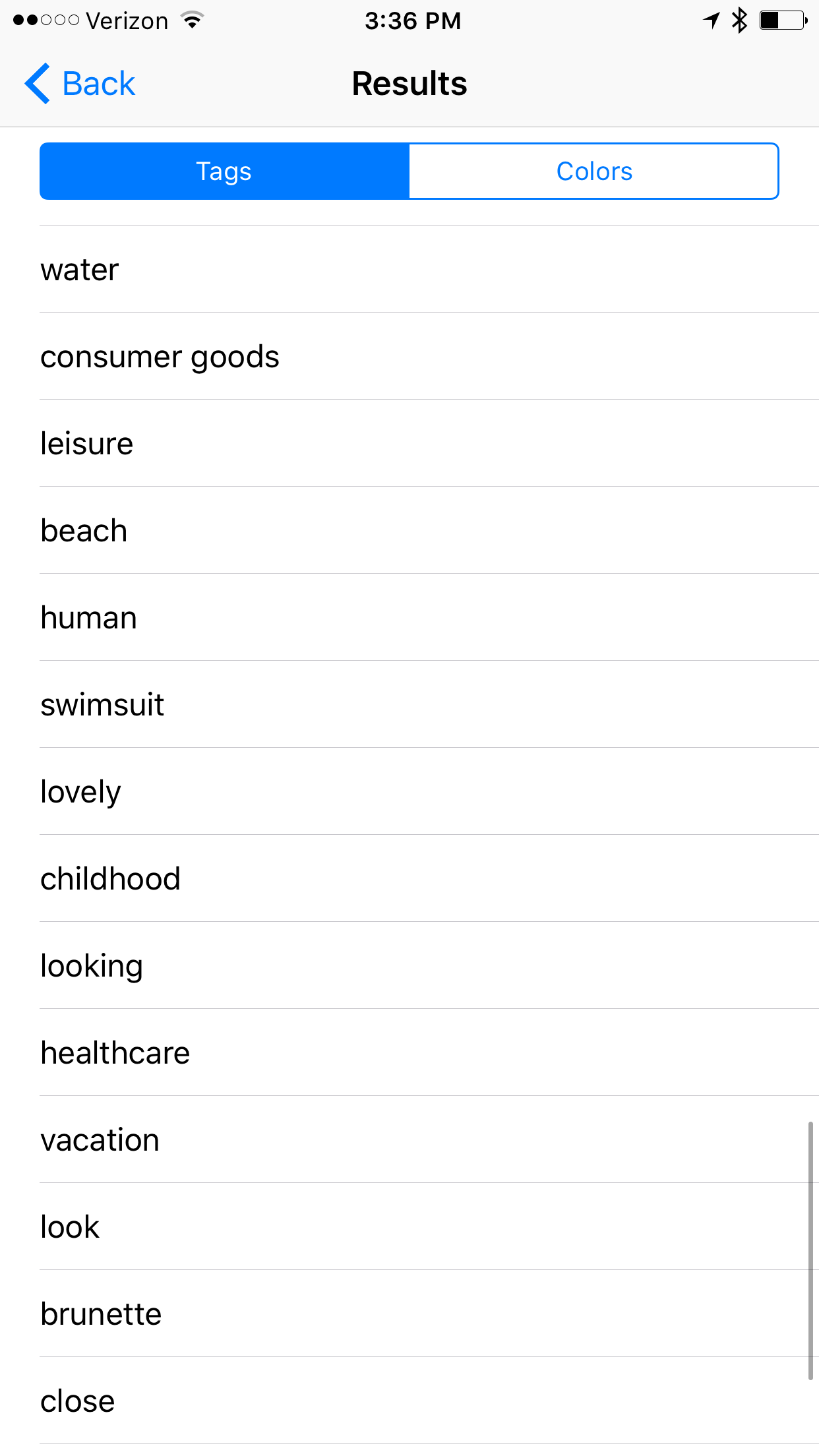
Notable Results: caucasian, attractive, adult, sexy, lady, fashion,
Once again more measures of attractiveness. Is their a correlation in this algorithm between gender/racial ideals of beauty?
Example #5


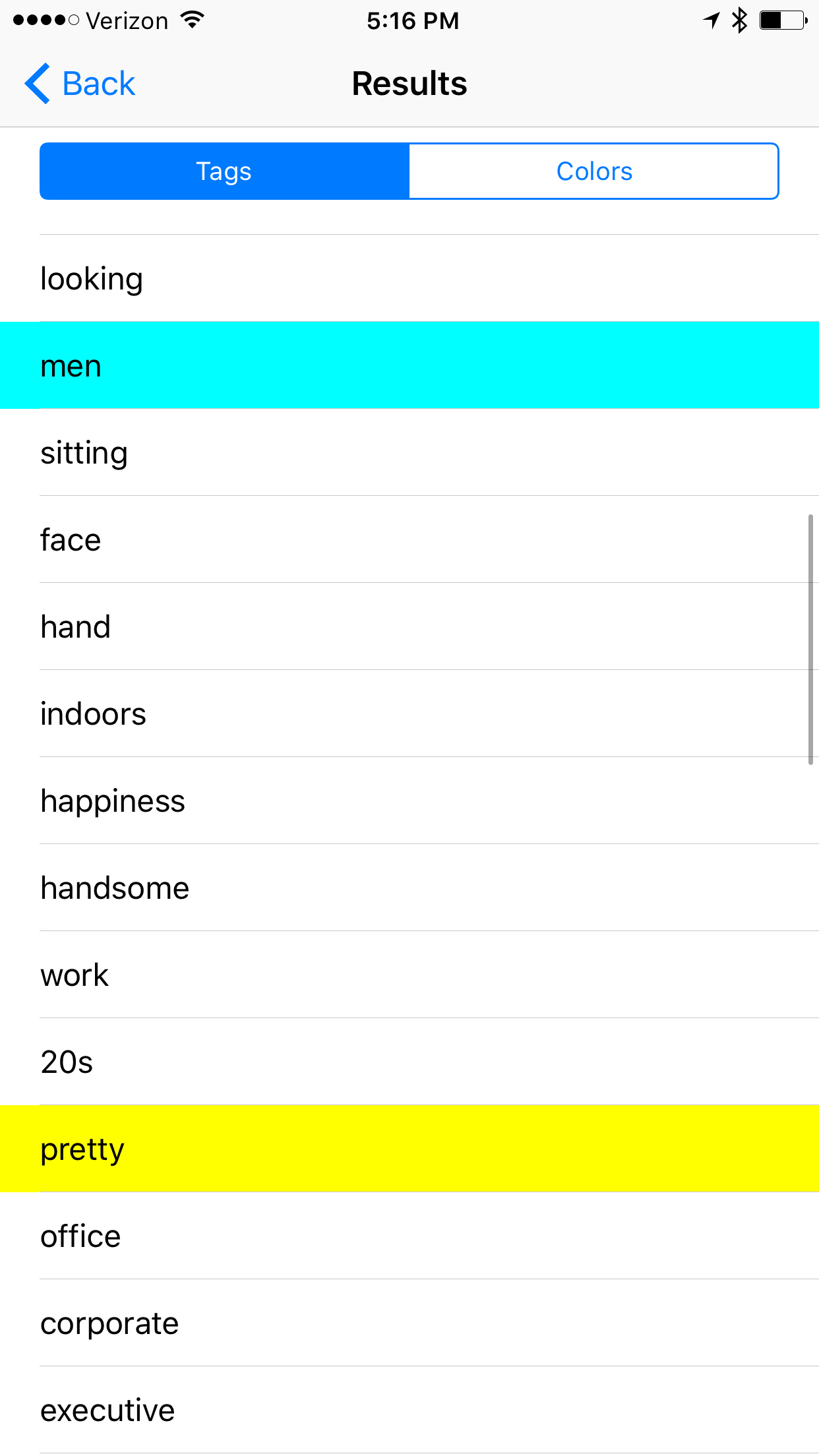
Notable Results: high confidence results for white adult male, attractive, business, handsome, pretty, corporate, executive.
We are seeing some qualitative appearance results, but dramatically fewer than the females. Seeing more business related terms as well, which comes in contrast with female career results.
Example: Dog Tax!


Notable Results: It did do an amazing job recognizing that Ellie is, in fact, a Chesapeake Bay Retriever. (Also a possible hippo)
I will continue to submit more images and log their results(hopefully with some more diversity in the next round). As technology progresses and becomes even more pervasive in our lives it becomes important to review the ethical implications along the way. This sample size was too low to make any broader claims, but for me it points to some questions we should ask ourselves about the relationship between technology and human constructs such as race or gender.
Do you have any concerns on the future of AI? Leave your comments below!
We will be adding future content at AIBias.com
AI Bias - Questions on the Future of Image Recognition
I'm interested in collaborating on a project about Bias in AI. I made a prototype of an Image Recognition app that detects and classifies objects in a photo. After a running a few tests I began to notice that race and gender were categories that occasionally would appear.
This made me more broadly curious about the practical implications of how AI/Machine Learning is designed and implemented, and the impact these choices could have in the future. There are many different image recognition platforms available to developers that approach the problem in differing ways. Some utilize metadata from curated image datasets, some use images shared on social media, and some use human resources(Mechanical Turk) to tag photos. How do these models differ with respect to inherent cultural, religious, and ethnic biases? The complicated process of classifying abstract more notions such as race, gender or emotion leave a lot of interpretation up to the viewer. Not to mention, the problem of the Null Set, in which ambiguous classifications may not be tagged leaving cruical information out of predictive models.
As a result of these different modes of classification:
What does this AI think a gender, or a race are?
How is the data seen as significant, and under what circumstances should it be used?
Should AI be designed such that it is "color blind"?
Please let me know your thoughts in the comments below!
If you are interested in collaborating, or playing with the prototype that led to this discussion, join the mailing list at AIBias.com or Showblender.com


Tech Note: Christie Spyder x20 VI Vertical Pixel Threshold Still Functionality
There is a known issue with x20 hardware which limits how Still Layers can be used in certain High Rez setups.
When configuring a frame with a VI Vertical Pixel count above 1850 pixels in Height, the system becomes limited with how it can utilize Still Stored images.
Only layers 3,6,11, and 14 can be used as still layers. Using other layers will induce strange behavior, including cropping, random noise, and other various errors when adjusting Keyframe parameters.
This is a hardware limitation with all x20s and all versions of Vista Advanced.
TL;DR-Exact wording via Vista Systems: "If the vertical height is higher than 1850 only layers 3,6,11,14 can load stills. This is a hardware limitation for any version software."
I have also heard people suggest this limit was at 1856 pixels. YMMV.
Sneak Peek - BlendBuddy 2.0 coming to Linux!
Tested on Ubuntu 12.04
Even iOS is on the way!

Generative Art Break







A quick peek at some abstract generative visuals I'm working on.
Controlling Video Playback via Christie Spyder
Today we are using openFrameworks to build a cross-platform Video playback solution that can be used by Spyder operators to sync playback from a Command Key. We use external network function keys to send specially formatted UDP commands to a custom video playback application. In this video we cycle through 3 separate looping video clips(P1-ShowBlender, P2-Walking Fingers, and P3-Vector Tree Animation) triggered from Vista Advanced 4.0.6.
Let me know if you have any playback integration needs.
Realtime 3D-Generating live 3d Meshes from Camera input
Here we utilize Open Frameworks to generate Real-time 3D renderings of a live webcam. By using the relative brightness between flesh tones, a mesh was generated by extruding these RGB values as depth. The responding images greatly exaggerate facial features and gestures.