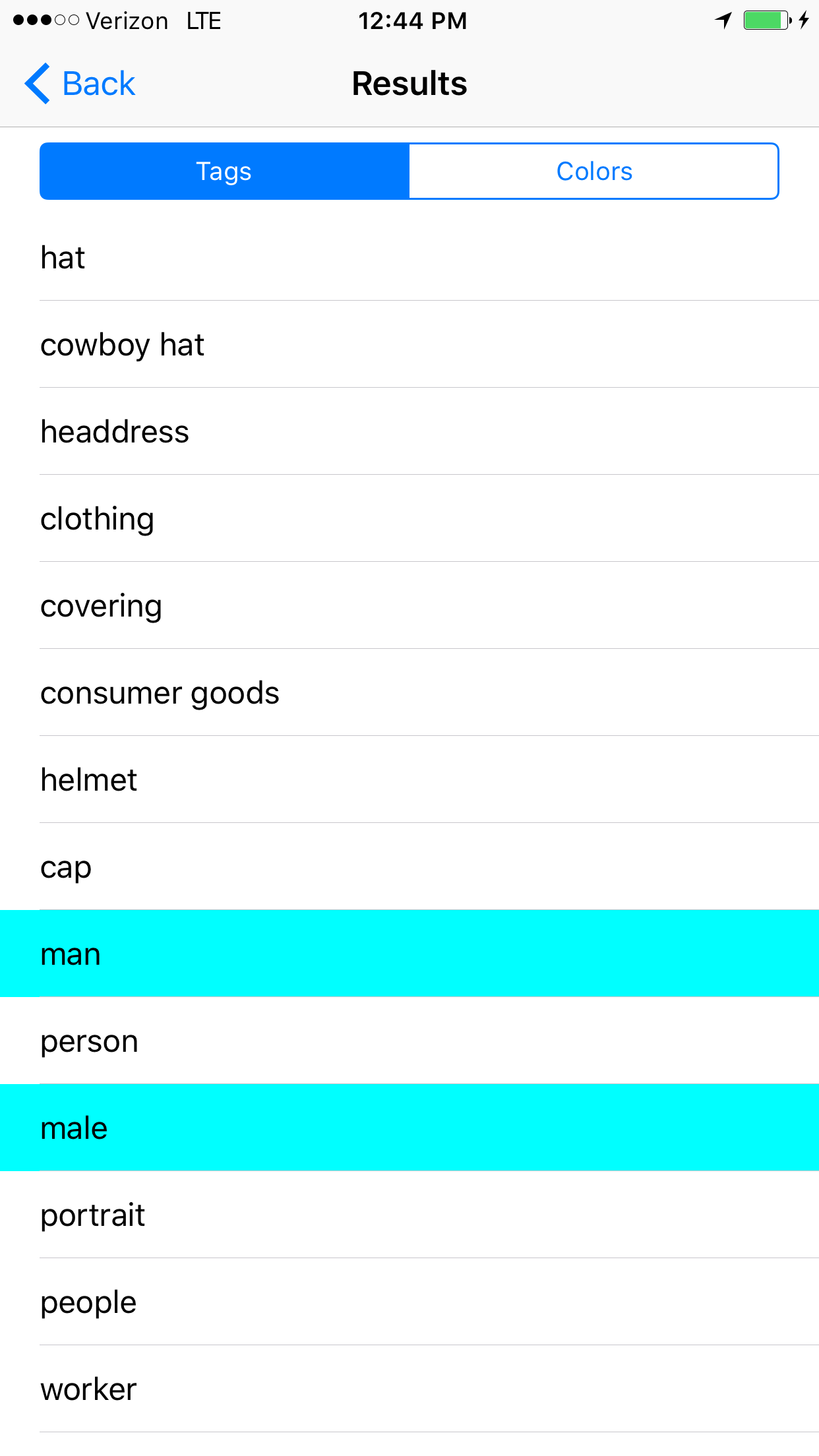
I'm interested in collaborating on a project about Bias in AI. I made a prototype of an Image Recognition app that detects and classifies objects in a photo. After a running a few tests I began to notice that race and gender were categories that occasionally would appear.
This made me more broadly curious about the practical implications of how AI/Machine Learning is designed and implemented, and the impact these choices could have in the future. There are many different image recognition platforms available to developers that approach the problem in differing ways. Some utilize metadata from curated image datasets, some use images shared on social media, and some use human resources(Mechanical Turk) to tag photos. How do these models differ with respect to inherent cultural, religious, and ethnic biases? The complicated process of classifying abstract more notions such as race, gender or emotion leave a lot of interpretation up to the viewer. Not to mention, the problem of the Null Set, in which ambiguous classifications may not be tagged leaving cruical information out of predictive models.
As a result of these different modes of classification:
What does this AI think a gender, or a race are?
How is the data seen as significant, and under what circumstances should it be used?
Should AI be designed such that it is "color blind"?
Please let me know your thoughts in the comments below!
If you are interested in collaborating, or playing with the prototype that led to this discussion, join the mailing list at AIBias.com or Showblender.com